An Interim Report from Practice
Many organizations manage a large number of PDF documents: fact sheets, guidelines, regulations, directives, laws, and standards. These documents are binding—for both internal staff and external partners—but are often difficult to access in everyday work. This is exactly where a current client project by mp technology comes in.
Initial Situation and Objectives
Our client wanted a chatbot that:
- provides well-founded, reliable answers
- explicitly references relevant documents and chapters
- can be used by internal employees as well as external users
The challenge: the underlying PDF documents are not uniform in structure, but consist largely of highly structured texts with clear hierarchies, tables, and references.
Semantic Chunking Instead of Simple Text Splitting
To make content usable for Retrieval-Augmented Generation (RAG), documents must be broken down into smaller units—so-called chunks. Instead of purely length-based chunking with overlaps, we rely on custom semantic chunking that preserves the original document structure as much as possible.
Specifically, content is modeled as a tree structure with up to four levels:
- Document
- Chapter
- Subchapter
- Sub-subchapter
Each chunk is aware of its structural context, which can be explicitly used when answering questions. Because each chunk covers a self-contained topic, vector similarity search on embeddings works far more accurately than with overlapping text fragments.
In addition, documents are assigned to thematic categories. A single document can belong to multiple topics at the same time.
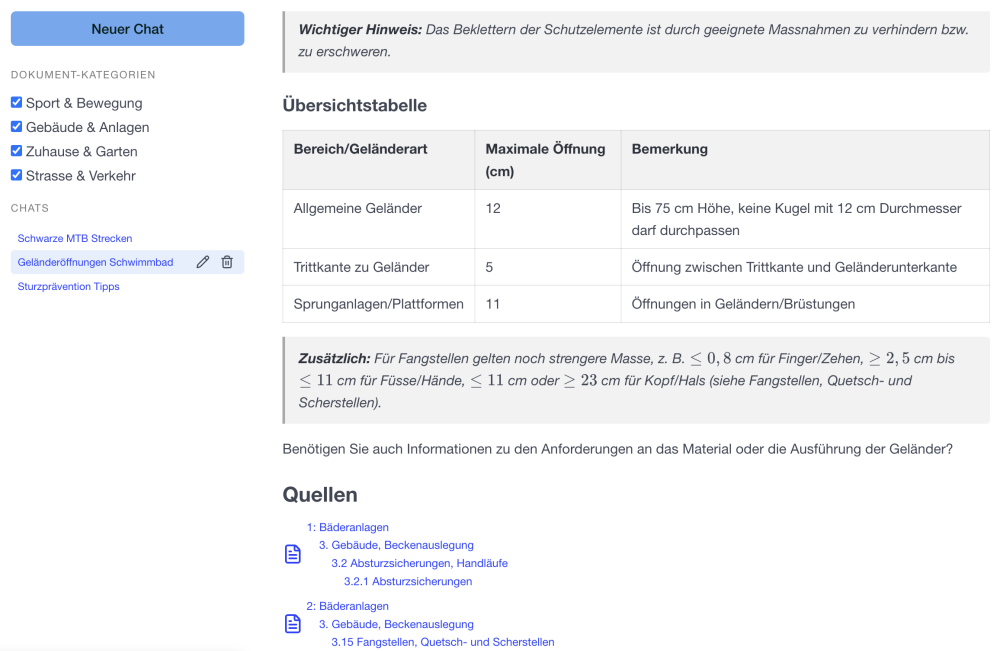
Transparency During Ingestion Is Critical
During development, one thing became clear very quickly:
Without transparency in the PDF conversion and chunking process, quality cannot be controlled.
Only when it is visible
- where structure is lost
- whether tables are processed correctly
- whether document hierarchies are detected accurately
can systematic weaknesses be identified.
Errors introduced during ingestion inevitably lead to incorrect or incomplete answers later on.
PDF Conversion: No Tool Is Perfect
No conversion library is reliable in all cases—especially when it comes to tabular content. During the pilot phase, we evaluated Docling, an open-source component from IBM. While the initial results were promising, closer inspection revealed significant shortcomings in the conversion of table-based structures.
We are currently using Marker via the Datalab API, which delivers more robust results for our use case. That said, it is equally clear that this solution is not perfect either.
Our approach therefore consists of two steps:
- automated correction of systematic issues
- manual cleanup of isolated errors
Only then is a document admitted into the curated corpus, in the best possible quality.
Modularity as a Strategic Decision
Whether it is the document converter, the embedding model, or the LLM:
The pace of innovation is extremely high. It is obvious that better components will emerge within months.
That is why our architecture is strictly modular. Individual components can be replaced with minimal effort, without reworking the entire system.
Technology Stack
The current solution is based on a proven open-source stack:
- FastAPI for the API layer
- LangGraph for orchestration and control flows
- PostgreSQL with pgvector for vector search
- Redis for caching and state management
Conclusion
A powerful RAG solution does not start with the chatbot—it starts with clean, well-structured knowledge ingestion. Structure, transparency, and curation are essential to delivering reliable answers.
This interim report shows: the effort pays off—and lays the foundation for a system that can grow with future requirements.


