Ein Zwischenbericht aus der Praxis
Unser Kunde verfügt über eine grosse Anzahl an PDF-Dokumenten: Merkblätter, Wegleitungen, Reglemente, Richtlinien, Gesetze und Standards. Diese Dokumente sind verbindlich – sowohl für interne Mitarbeitende als auch für externe Partner – aber so umfangreich, dass oft nur ExpertInnen wissen, welche Informationen für eine gegebene Fragestellung relevant sind und wo diese zu finden sind. Genau hier setzt ein aktuelles Kundenprojekt von mp technology an.
Ausgangslage und Zielsetzung
Unser Kunde wünschte sich einen AI Chatbot, der:
- fundierte, nachvollziehbare Antworten liefert
- konkret auf relevante Dokumente und Kapitel verweist
- sowohl von internen Mitarbeitenden als auch von Externen genutzt werden kann
Die Herausforderung: Die zugrunde liegenden PDF-Dokumente sind nicht einheitlich aufgebaut, bestehen aber grösstenteils aus hoch strukturierten Texten mit klaren Gliederungen und Tabellen.
Semantisches Chunking statt einfacher Textzerlegung
Damit Inhalte für Retrieval-Augmented Generation (RAG) nutzbar sind, müssen sie in kleinere Einheiten – sogenannte Chunks – aufgeteilt werden. Anstelle von rein längenbasiertem oder generischem hierarchischem Chunking mit Overlaps setzen wir auf ein custom semantisches Chunking, das die ursprüngliche Dokumentstruktur möglichst vollständig erhält.
Konkret werden die Inhalte als Baumstruktur mit bis zu vier Ebenen modelliert:
- Dokument
- Kapitel
- Unterkapitel
- Unterunterkapitel
Jeder Chunk kennt seinen strukturellen Kontext. Dieser kann bei der Beantwortung von Fragen gezielt mitverwendet werden. Da jeder Chunk ein in sich geschlossenes Thema behandelt, funktioniert die Vector Similarity Search auf Embeddings deutlich treffsicherer als bei überlappenden Textfragmenten.
Zusätzlich sind die Dokumente in Themenbereiche gegliedert – ein Dokument kann dabei mehreren Themen gleichzeitig zugeordnet sein und die Suche auf spezifische Themenbereiche beschränkt werden.
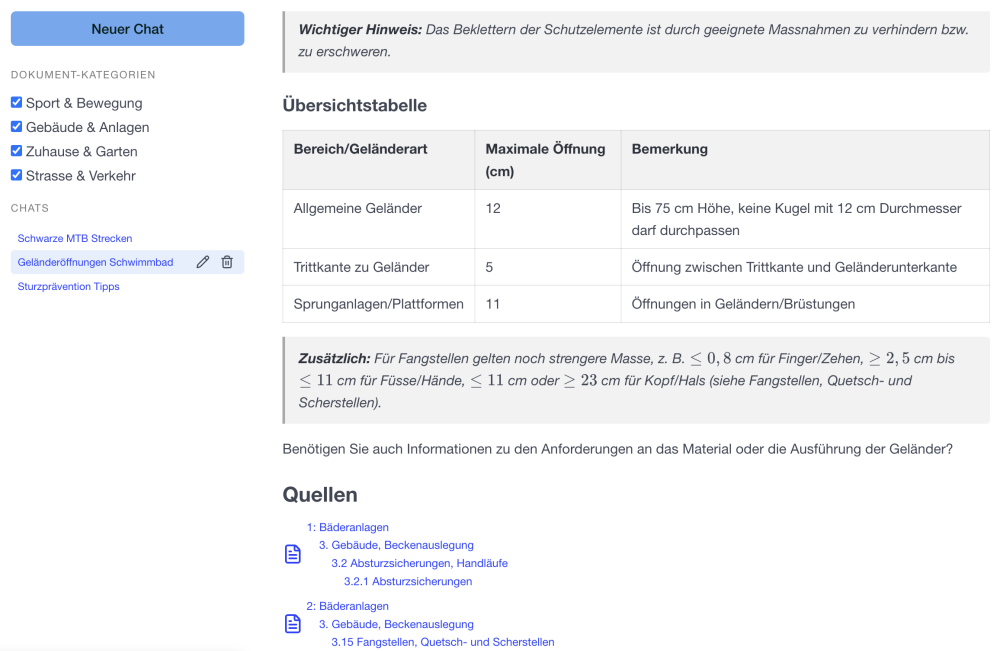
Transparenz in der Ingestion ist entscheidend
In der Entwicklung hat sich sehr schnell gezeigt – Ohne Transparenz im PDF-Konvertierungs- und Chunking-Prozess ist Qualität nicht kontrollierbar.
Nur wenn sichtbar ist,
- wo Struktur verloren geht
- ob Tabellen korrekt interpretiert werden
- ob Gliederungen richtig erkannt werden
lassen sich systematische Schwächen identifizieren.
Fehler, die bereits bei der Ingestion entstehen, führen später zwangsläufig zu falschen oder unvollständigen Antworten im Chatbot.
PDF-Konvertierung: Kein Werkzeug ist perfekt
Keine Konverter-Library ist heute in allen Fällen zuverlässig – insbesondere bei tabellarisch strukturierten Texten. In der Pilotphase haben wir unter anderem Docling, eine Open-Source-Komponente von IBM, evaluiert. Erste Ergebnisse waren vielversprechend, bei genauerer Analyse zeigten sich jedoch deutliche Schwächen bei Tabellen.
Aktuell setzen wir auf Marker via Datalab API, das in unserem Szenario robustere Resultate liefert. Gleichzeitig bleibt klar: Auch diese Lösung ist nicht perfekt.
Deshalb ist unser Ansatz zweistufig:
- systematische Mängel automatisiert korrigieren
- punktuelle Fehler manuell bereinigen
Erst danach wird ein Dokument in den kuratierten Korpus übernommen – in der qualitativ bestmöglichen Form.
Modularität als strategische Entscheidung
Ob Dokument-Konverter, Embedding-Modell, Reranker oder LLM:
Der Markt entwickelt sich rasant. Es ist absehbar, dass in wenigen Monaten neue, bessere Komponenten verfügbar sein werden.
Unsere Architektur ist deshalb konsequent modular aufgebaut. Einzelne Bausteine können mit überschaubarem Aufwand ersetzt werden, ohne das Gesamtsystem neu denken zu müssen.
Technologie-Stack
Die aktuelle Lösung basiert auf einem bewährten Open-Source-Stack:
- FastAPI
- LangGraph
- PostgreSQL mit pgvector
- Redis für Caching und State-Management
Fazit
Eine leistungsfähige RAG-Lösung beginnt nicht beim AI Chatbot, sondern bei der sauberen Aufbereitung der Wissensbasis. Struktur, Transparenz und Kuration sind entscheidend, um verlässliche Antworten liefern zu können.
Dieser Zwischenbericht zeigt: Der Aufwand lohnt sich – und bildet die Grundlage für ein System, das mit den Anforderungen wächst.


